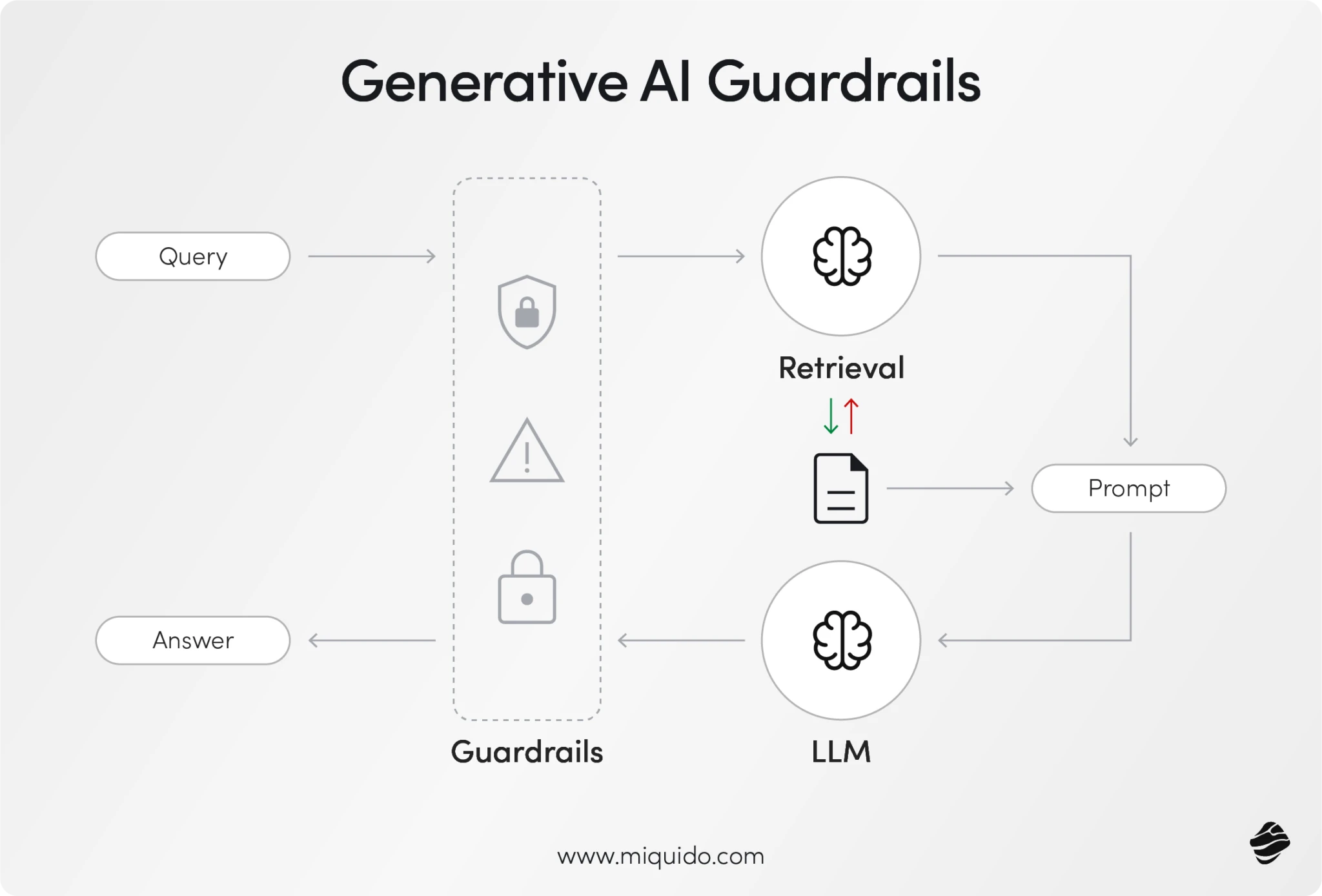
Multi-Agent Collaboration Without Fixed Orchestration - Hợp tác AI Agent không thông qua điều phối
Ý tưởng về “multi-agent collaboration without fixed orchestration” ra đời để giài quyết vấn đề đi theo một luồng cố định, các AI Agent được thiết kế để phối hợp linh hoạt, tương tác tự nhiên và tự tổ chức nhằm đạt mục tiêu chung.
Tác giả
Vy Nguyen
Table of Contents
Khái niệm
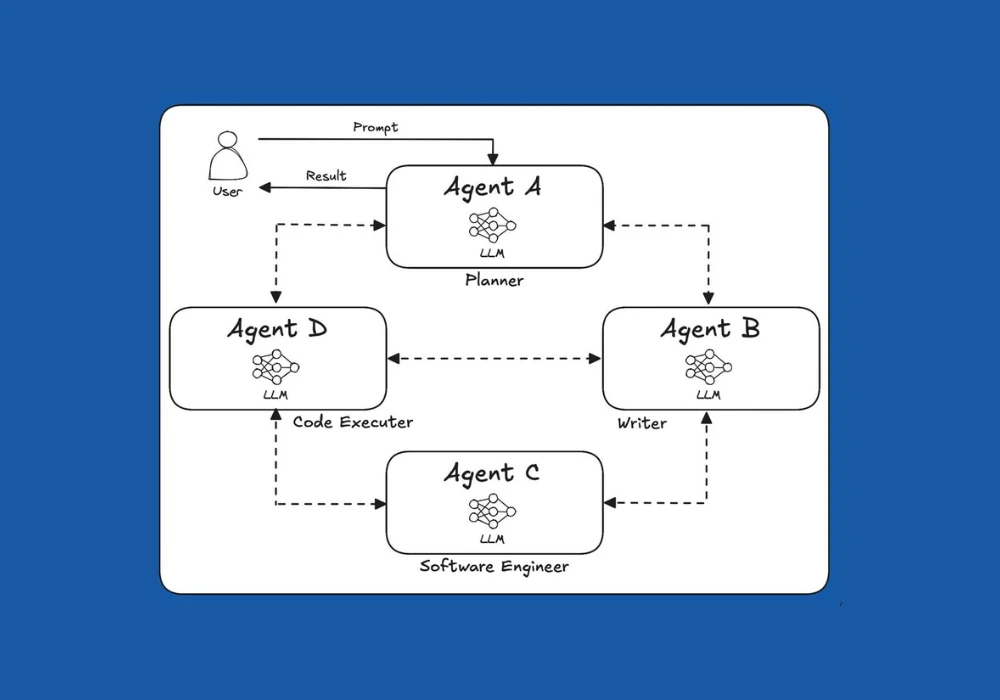
Trong thế hệ hiện nay, hầu hết các AI Agent vẫn được thiết kế theo một luồng làm việc cố định. Mỗi Agent được gắn vào một vị trí trong pipeline, nhận đầu vào, xử lý, rồi chuyển kết quả sang Agent tiếp theo. Cấu trúc này giúp kiểm soát quy trình dễ dàng, nhưng lại thiếu khả năng thích ứng khi môi trường hoặc nhiệm vụ thay đổi. Một khi flow bị phá vỡ, toàn bộ hệ thống có thể ngừng hoạt động hoặc cần can thiệp thủ công để khôi phục.
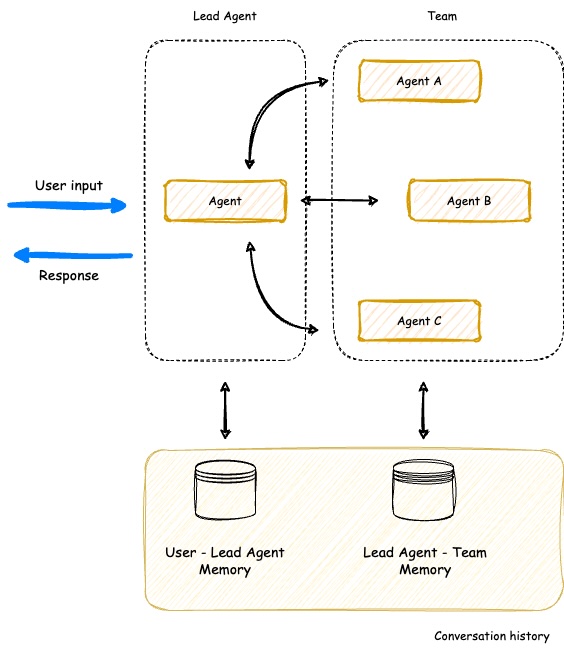
Ý tưởng về “multi-agent collaboration without fixed orchestration” ra đời để giải quyết chính giới hạn đó. Thay vì phải đi theo một luồng cố định, các AI Agent được thiết kế để phối hợp linh hoạt, tương tác tự nhiên và tự tổ chức nhằm đạt mục tiêu chung. Mỗi Agent có thể phát hiện nhiệm vụ mới, trao đổi thông tin, đề xuất hướng giải quyết, và hỗ trợ Agent khác mà không cần một orchestrator trung tâm điều khiển. Điều này khiến hệ thống vận hành gần giống một nhóm con người cùng làm việc, nơi từng thành viên hiểu rõ mục tiêu, có năng lực riêng, và biết khi nào nên hành động hay lùi lại.
Nguyên tắc hoạt động
Cơ chế hoạt động của mô hình này dựa trên ba nguyên tắc chính.
- Thứ nhất là shared goal space, tức tất cả Agent cùng hiểu mục tiêu tổng thể và trạng thái hiện tại của công việc.
- Thứ hai là dynamic role assignment, mỗi Agent có thể tự nhận vai trò phù hợp với năng lực và ngữ cảnh, thay vì được lập trình cố định.
Thứ ba là adaptive communication, nghĩa là các Agent có thể thương lượng, đặt câu hỏi, hoặc trao đổi dữ liệu một cách tự nhiên thông qua các thông điệp được mã hóa theo ngữ nghĩa. Khi ba lớp này kết hợp, hệ thống sẽ dần hình thành một cơ chế phối hợp mềm dẻo, tương tự “tập thể biết tự điều tiết”.
Rủi ro
Tuy nhiên, việc loại bỏ flow cố định không hề đơn giản. Khi không có một orchestrator trung tâm, nguy cơ conflict và redundancy tăng cao. Hai Agent có thể cùng xử lý một nhiệm vụ hoặc đưa ra các quyết định trái ngược nhau. Để tránh điều đó, cần có các cơ chế thương lượng (negotiation protocol) hoặc đồng thuận (consensus mechanism) cho phép các Agent thống nhất hướng hành động. Ngoài ra, hệ thống cũng phải có contextual awareness để biết nhiệm vụ nào đang diễn ra, ai đang xử lý phần nào và khi nào nên chuyển vai trò.
Một điểm quan trọng khác là communication efficiency. Trong mô hình này, các Agent liên tục trao đổi thông tin, nếu không kiểm soát tốt thì chi phí truyền thông có thể bùng nổ. Các phương pháp phổ biến để giảm tải gồm event-driven messaging, chỉ gửi thông điệp khi có sự kiện mới; publish-subscribe, nơi Agent đăng ký nhận loại thông tin phù hợp; và stigmergy, lấy cảm hứng từ sinh học, nơi các Agent để lại dấu hiệu trong môi trường để các Agent khác dựa vào đó mà hành động.
Bên cạnh đó, mỗi Agent cần có khả năng ghi nhớ và học hỏi từ kinh nghiệm trước đó. Một số hệ thống dùng shared memory để lưu lại toàn bộ lịch sử chung, trong khi các hệ thống khác cho phép local memory riêng biệt và chỉ đồng bộ thông tin quan trọng. Việc này giúp các Agent rút kinh nghiệm, tránh lặp lại lỗi cũ và thích ứng dần theo môi trường.
Nhiều công trình nghiên cứu đã thử nghiệm cách tiếp cận này. Ví dụ, mô hình Puppeteer sử dụng reinforcement learning để xác định Agent nào nên hành động ở thời điểm cụ thể nhằm tối ưu hiệu suất chung. Mô hình Federation cho phép mỗi Agent tự mô tả năng lực của mình bằng capability vector, giúp hệ thống tự động định tuyến nhiệm vụ đến Agent phù hợp nhất. Mô hình DRAMA tách phần điều khiển (control plane) và phần thực thi (worker plane), giúp hệ thống có thể tái phân công nhiệm vụ khi môi trường thay đổi. Một số nhóm khác phát triển mô hình Cross-team collaboration, trong đó nhiều nhóm Agent hoạt động song song và chia sẻ kết quả để học hỏi lẫn nhau mà không cần điều phối cứng.
Lợi ích
Lợi ích của phương pháp này rất rõ ràng. Hệ thống trở nên linh hoạt, dễ mở rộng, giảm phụ thuộc vào một điểm lỗi trung tâm và có khả năng xử lý các nhiệm vụ phức tạp theo cách phi tuyến tính. Tuy nhiên, nó cũng mang lại nhiều thách thức trong kiểm soát và đánh giá. Khi các Agent được trao quyền tự quyết cao, việc dự đoán hành vi tổng thể trở nên khó khăn hơn, đồng thời việc gỡ lỗi hoặc truy xuất nguyên nhân của một quyết định sai cũng phức tạp hơn.
Trong tương lai, các hướng phát triển tập trung vào learnable orchestration, tức là để các Agent học cách phối hợp qua thời gian thay vì được thiết kế sẵn. Các nghiên cứu cũng hướng đến semantic routing, nơi hệ thống chọn Agent phù hợp dựa trên ngữ nghĩa nhiệm vụ thay vì chỉ dựa vào loại dữ liệu. Bên cạnh đó là meta-learning, giúp các Agent không chỉ học cách làm việc mà còn học cách học lẫn nhau. Một vấn đề quan trọng khác là đảm bảo safety and transparency, vì hệ thống phi tập trung cần có giới hạn để tránh các hành vi ngoài dự kiến.
Tổng kết lại, multi-agent collaboration without fixed orchestration đại diện cho một bước tiến lớn trong cách chúng ta hình dung sự hợp tác giữa các AI Agent. Đây không còn là mô hình pipeline cố định, mà là một hệ sinh thái sống, nơi từng Agent có thể nhận thức, học hỏi, phản ứng và hỗ trợ nhau để cùng hoàn thành mục tiêu chung. Khi công nghệ này trưởng thành, chúng ta có thể thấy những nhóm Agent làm việc cùng nhau như một đội con người thật, không cần flow, không cần lệnh điều phối, mà vẫn đạt hiệu quả tối đa.